Project
如何设计秒杀系统
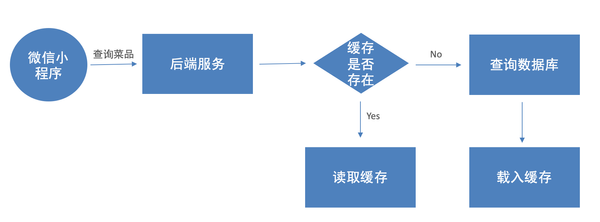
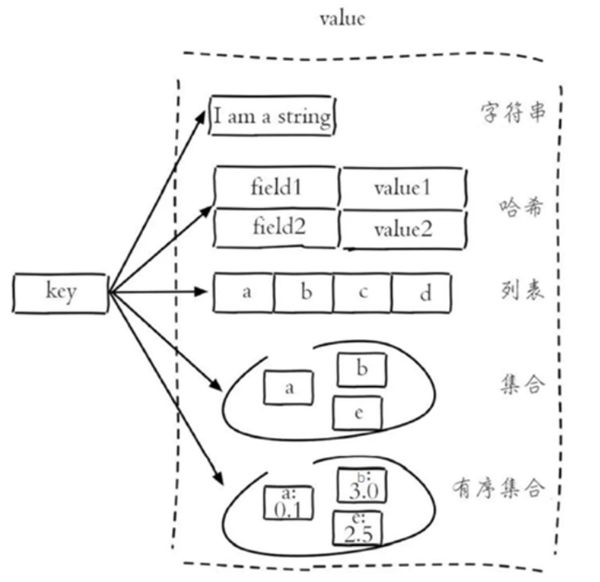
什么是秒杀设计 秒杀设计 是一种针对高并发、大流量场景的系统设计,通常应用于电商活动中(如限时抢购、促销等),用户在非常短的时间内大量涌入系统,抢购有限的商品或优惠。这种场景下,系统需要能够承受巨大的瞬时并发请求,同时保证数据的一致性和业务的正确性。 秒杀技术分析 秒杀系统贯穿活动、商品和下单三个领域,涵盖了页面静态化、接口限流、Redis预减库存、异步下单和接口动态化等技术。 需要迎接的挑战有: 1. 高并发和压力测试:秒杀活动会带来巨大的流量,服务器和数据库的并发处理能力是关键。 2. 保证数据一致性:抢购涉及到商品库存的实时减少,需要保证在高并发场景下库存数据的准确性和一致性 3. 防止超卖和重复购买:确保同一商品不会被重复购买,同时避免超卖,即使是在极端的高并发情况下 4. 分布式锁和限流:使用分布式锁来保护关键资源,限制用户访问频率以免系统崩溃 5. 性能优化:包括代码层面的优化、数据库的优化、缓存的使用等,以提高系统性能和响应速度。 页面静态化 秒杀页面静态化是将动态生成的秒杀页面转换为静态HTML页面,从而提高页面响应速度和系统性能