外卖点餐系统05
Redis简介
Redis在MySQL基础上提高数据存取效率
Redis是一个基于内存的key-value结构数据库。
MySQL是基于磁盘实现的数据库,由于数据读写需求越来越大,这种基于磁盘的读取速度就不够了,于是是否能够像CPU一样为了提高速度,也搞一个类似内存的东西。于是Redis就产生了。
应用程序从MySQL查询到的数据在Redis中进行登记,后续再查询数据先搜索Redis,Redis没有再搜索MySQL。
Redis缓存内容设置超时时间
Redis缓存的数据都是在内存上,但是内存的空间资源很有限,所以需要给缓存内容设置一个超时时间,具体设置多久交给应用程序设置,Redis只需要在时间过期后及时删除数据。
Redis删除策略
- 定期删除,eg:每100ms随机清理部分缓存数据,这里不清理所有Redis内存过期数据,是因为全面扫描一遍需要时间过久
- 但是由于随机算法,有可能使得某些键值长期不被随机到,未被清理
- 触发删除,为了避免有些键值长期不被清理,于是有了出发删除
- 主动发起请求检查key是否过期,如果过期立马删除,这种方式因为是被动方式出发,不查询就不会发生,所以也叫惰性删除
- 但是仍有些键值,既逃脱了随机算法也没有被查询。
- 内存淘汰策略——万一过期时间设置的很长,没有等到定时清理,内存就满了
- allkeyS-LRU:使用LRU算法删除最近最少使用的键值
- volatile-lru:使用LRU算法从设置了过期时间的键集合中删除最近最少使用的键值
- ...
Redis缓存穿透
问题:有时候查询的数据MySQL不存在,redis中肯定也没有,MySQL也会执行一次空查询,Redis根本没起作用,这就是Redis穿透。
解决:布隆过滤器,擅长从超大的数据集中快速告诉你查找的数据不存在
Redis缓存雪崩
问题:一大批数据几乎同时过了有效期,又发生了很多对这些数据的请求
解决方法:把键值的过期时间进行随机,并设置热点数据永不过期
Redis总结
Redis是一个基于内存的key-value结构数据库。
- 基于内存存储,读写性能高
- 适合存储热点数据(热点商品、资讯、新闻)
- 企业应用广泛
Redis常用数据类型介绍
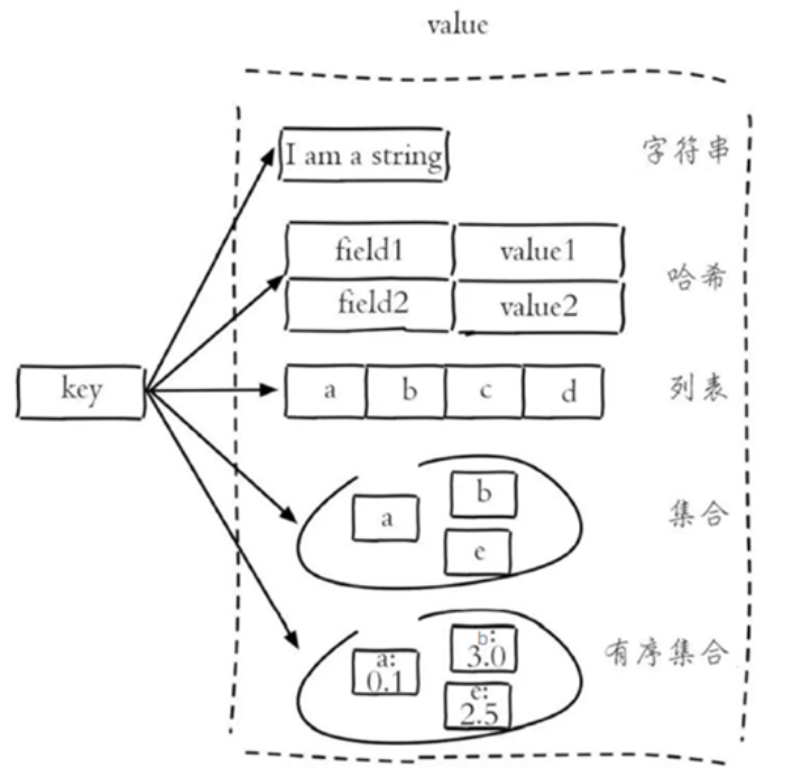
Redis存储的是key-value结构的数据,其中key是字符串类型,value有5种常用的数据类型:
- 字符串string:普通字符串,Redis种最简单的数据类型
- 哈希hash:类似于Java中的HashMap结构,适合存储对象
- 列表list:是一个简单的字符串列表,按照插入顺序排序,可以有重复元素,类似于Java中的LinkedList
- 集合set:string类型的无序集合,没有重复元素,类似于Java中的HashSet,可以进行集合运算,求交集,应用场景:朋友圈共同点赞朋友。
- 有序集合 sorted set:string类型元素的有序集合,集合中每个元素关联一个分数(score),根据分数升序排列,没有重复元素,经典应用场景:排行榜

value-字符串string 操作命令
- set key value 设置指定key的值
- get key 获取指定key的值
- setex key seconds value 设置指定的key值,并将key的过期时间设置为seconds秒,(Set with Expiry)典型应用场景:短信验证码
- setnx key value 只在key不存在时设置key的值,应用场景:分布式锁
value-哈希hash
- hset key field value 将哈希表key中的字段field的值设为value
- hget key field 获取存储在哈希表中指定字段的值
- hdel key field 删除存储在哈希表中的指定字段
- hkeys key 获取哈希表中所有字段,返回所有的field
- hvals key 获取哈希表中所有值,返回所有的value
列表list
- lpush key value1 [value2] 将一个或多个值插入到列表头部,lpush中的l是left
- lrange key start stop 获取列表指定范围内的元素
- rpop 移除并获取列表最后一个元素
- llen key 获取列表长度
集合set
- sadd key member1 [member2] 向集合添加一个或多个成员,sadd key1 xiaoming xiaohong
- smembers key 返回集合中所有成员
- scard key 获取集合的成员数
- sinter key1 [key2] 返回给定所有集合的交集
- sunion key1 [key2] 返回所有给定集合的并集
- srem key member1 [member2] 删除集合中一个或多个成员,rem代表remove
有序集合 sorted set
- zadd key socre1 member [score2 member2] 向有序集合添加一个或多个成员
- zrange key start stop [withscores] 通过索引区间返回有序集合中指定区间内的成员,增加withscores会在返回成员的同时返回分数, zrange key 0 -1(返回key所有成员)
- zincrby key increment member 有序集合中对指定成员member的分数加上增量increment
- zrem key member [member ...] 删除集合中的一个或多个成员
通用命令
Redis的通用命令不分数据类型,都可以使用的命令:
- keys pattern 查找所有符合给定模式(pattern)的key (keys *)返回所有key
- exists key 检查给定key是否存在
- type key 返回key所存储的值的类型
- del key 该命令用于在key存在时删除key
在Java中操作Redis
Spring Data Redis
Spring Data Redis的使用方式:
- 导入Spring Data Redis的maven坐标——在项目依赖文件pom.xml中添加相应依赖
<!-- sky-server的pom.xml文件 -->
<!-- Spring Data Redis -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
spring-boot-starter-data-redis 没有指定版本号。这可能是因为通过 Spring Boot 依赖管理,它会自动选择合适的 Redis 版本。如果你在父工程的
- 配置Redis数据源
配置文件中(application.yml)配置本地Redis端口号,用户名和密码
spring:
redis:
host: localhost
port: 6379
password:
database:
- 编写配置类,创建RedisTemplate对象
@Configuration
@Slf4j
public class RedisConfiguration {
@Bean
// 依赖文件pom.xml中的,spring-boot-starter-data-redi会将连接工厂对象创建好,并放入spring容器当中
// RedisConnectionFactory 是redis连接工厂对象,这里是通过spring Bean注解按照类型注入的
public RedisTemplate redisTemplate(RedisConnectionFactory redisConnectionFactory) {
// 该方法返回redisTemplate对象,后续利用RedisTemplate对象操作Redis
RedisTemplate redisTemplate = new RedisTemplate();
// 让redisTemplate关联上redis连接工厂对象
redisTemplate.setConnectionFactory(redisConnectionFactory);
// 设置redis key的序列化器
redisTemplate.setKeySerializer(new StringRedisSerializer());
return redisTemplate;
}
}
- 通过RedisTemplate对象操作Redis
@SpringBootTest
public class SpringDataRedisTest {
@Autowired
private RedisTemplate redisTemplate;
@Test
public void testRedisTemplate() {
// 使用redisTemplate操作redis数据对象
// 对应redis五种数据类型,每个类型都封装了接口
ValueOperations valueOperations = redisTemplate.opsForValue();
HashOperations hashOperations = redisTemplate.opsForHash();
ListOperations listOperations = redisTemplate.opsForList();
SetOperations setOperations = redisTemplate.opsForSet();
ZSetOperations zSetOperations = redisTemplate.opsForZSet();
}
/**
* 操作字符串类型的数据
*/
@Test
public void testString() {
// set get setex setnx
redisTemplate.opsForValue().set("city", "Beijing"); // set
String city = (String) redisTemplate.opsForValue().get("city"); //get
System.out.println(city);
redisTemplate.opsForValue().set("city1", "Shanghai", 4, TimeUnit.MINUTES); // setex
redisTemplate.opsForValue().setIfAbsent("province", "Hubei"); // setnx
redisTemplate.opsForValue().setIfAbsent("province", "Ningxia"); // setnx
}
}
-
为什么 redisTemplate 是通过配置类调用的
程序在 RedisConfiguration 中定义RedisTemplate Bean 并通过 @Bean 注解公开它时,Spring 自动将这个 Bean 加入到应用上下文。之后,无论是在应用主代码中还是在测试类中,只要你使用 @Autowired,Spring 都会自动注入相应的 Bean。
换句话说,SpringDataRedisTest 类并不需要手动调用 RedisConfiguration。Spring Boot 会自动加载并初始化这个配置类中的所有 Bean。@Autowired 注解会让 Spring 自动处理依赖注入,不需要开发者手动调用配置类中的方法。 -
Spring 容器如何管理 Bean?
Spring 容器在启动时会扫描所有带有 @Configuration 和 @Bean 注解的类,并将它们注册为 Spring 管理的 Bean。这些 Bean 会被自动装配到需要它们的地方(通过 @Autowired)。因此,在测试类SpringDataRedisTest中,Spring 容器在测试类启动时已经准备好了 RedisTemplate,并通过 @Autowired 注入到相应的字段。 -
总结
- 你在 RedisConfiguration 中定义了一个 RedisTemplate Bean。
- Spring 容器会自动识别并加载这个 Bean,注册到应用上下文中。
- 在测试类中,@Autowired 告诉 Spring 自动将 RedisTemplate 注入,无需手动调用配置类。
店铺营业状态设置
接口设计

店铺状态数据存储方式:基于Redis字符串数据存储
key: SHOP_STATUS value: 0 or 1
约定: 1表示营业,0表示打烊
代码开发
客户端商店相关接口开发
@RestController("adminShopController") // 这里是自定义了该Bean的名称,因为controller.admin和controller.user下
// 有同类名的ShopController,要将这两个类名在Spring Bean容器中区分开来
@RequestMapping("/admin/shop")
@Api(tags = "店铺相关接口")
@Slf4j
public class ShopController {
@Autowired
private RedisTemplate redisTemplate;
private static final String key = "SHOP_STATUS";
/**
* 设置店铺营业状态
* @param status
* @return
*/
@PutMapping("/{status}")
@ApiOperation("设置店铺营业状态")
public Result<String> setStatus(@PathVariable Integer status) {
log.info("店铺的营业状态为:{}", status == 1 ? "营业中" : "打烊中");
redisTemplate.opsForValue().set(key, status);
return Result.success();
}
/**
* 管理端查询营业状态
*/
@GetMapping("/status")
@ApiOperation("管理端查询营业状态")
public Result<Integer> getStatus() {
Integer status = (Integer) redisTemplate.opsForValue().get(key);
log.info("店铺营业状态:{}", status == 1 ? "营业中" : "打烊中");
return Result.success(status);
}
}
用户端查询店铺状态接口开发
@RestController("userShopController") // 这里是自定义了该Bean的名称,因为controller.admin和controller.user下
// 有同类名的ShopController,要将这两个类名在Spring Bean容器中区分开来
@RequestMapping("/user/shop")
@Api(tags = "店铺相关接口")
@Slf4j
public class ShopController {
@Autowired
private RedisTemplate redisTemplate;
private static final String key = "SHOP_STATUS";
/**
* 用户端查询营业状态
*/
@GetMapping("/status")
@ApiOperation("用户端查询营业状态")
public Result<Integer> getStatus() {
Integer status = (Integer) redisTemplate.opsForValue().get(key);
log.info("店铺营业状态:{}", status == 1 ? "营业中" : "打烊中");
return Result.success(status);
}
}