剑指offer 树
递归是一个过程或函数在其定义或说明中直接或间接调用自身的一种方法,它通常将一个大型复杂的问题层层转化为一个与原问题相似的规模较小的问题来求解。因此递归过程中,最重要的是查看 能否将问题分解为更小的子问题,这是使用递归的关键。
二叉树的递归,则是将某个节点的左子树、右子树看成一颗完整的树,那么对于子树的访问或者操作就是对于原树的访问或者操作的子问题,因此可以自我调用函数不断进入子树。
JZ55 二叉树的深度
思路一 —— 递归
二叉树的深度等于根节点这个1层加上左子树和右子树深度的最大值,即root_depth = max(left_depth, right_depth) + 1。而每个子树我们都可以看出一个根节点,于是我们可以对这个问题划分为子问题,利用递归来解决:
- 终止条件:当进入叶子节点后,再进入子节点,即为空,没有深度可言,返回0。
- 返回值:每一级按照上述公式,返回两边子树深度的最大值加上本级的深度,即加1。
- 本级任务:每一级的任务就是进入左右子树,求左右子树的深度。
import java.util.*;
/**
public class TreeNode {
int val = 0;
TreeNode left = null;
TreeNode right = null;
public TreeNode(int val) {
this.val = val;
}
}
*/
public class Solution {
public int TreeDepth(TreeNode root) {
if (root == null) return 0;
return Math.max(TreeDepth(root.left), TreeDepth(root.right)) + 1;
}
}
思路二 —— 队列 层次遍历
我们用队列对树进行层次遍历,第一层,根节点先入队,队列中只有一个节点,对应第一层只有一个节点,第一层访问结束后,第一层节点出队,它的子节点刚好都加入了队列,此时队列中的元素个数就是第二层的节点数。因此当我们使用队列对树进行层次遍历时,每遍历完一层节点深度就可以加1,直到遍历结束,即可得到最大深度。
知识点
Java专门维护了队列集合接口Queue,继承自Collection类
public interface Queue<E> extends Collection<E>
除了基本的收集操作外,队列还提供额外的插入、提取和检查操作。每种方法都有两种形式:一种是在操作失败时抛出异常,另一种是返回一个特殊值(空或假,取决于操作)。后一种形式的插入操作是专门为容量受限的队列实现而设计的;在大多数实现中,插入操作不会失败。
| Throws Exception | Returns special value | |
|---|---|---|
| Insert Operation | add(e) | offer(e) |
| Delete Operation | remove() | poll() |
| Examine Operation | element() | peek() |
本题代码,使用一个变量n记录树的每一层有多少个节点,然后队列中提取n个节点,就到了下一层的节点。
import java.util.*;
/**
public class TreeNode {
int val = 0;
TreeNode left = null;
TreeNode right = null;
public TreeNode(int val) {
this.val = val;
}
}
*/
public class Solution {
public int TreeDepth(TreeNode root) {
if (root == null) return 0;
Queue<TreeNode> q = new LinkedList<TreeNode>();
// 根节点入队
q.add(root);
int depth = 0;
while(!q.isEmpty()) {
// 定义一个变量记录每一层有多少个节点
int n = q.size();
for(int i = 0; i < n; i++) {
if(q.element().left != null) {
q.offer(q.element().left);
}
if(q.element().right != null) {
q.offer(q.element().right);
}
q.poll();
}
depth++;
}
return depth;
}
}
JZ27 二叉树的镜像
描述
操作给定的二叉树,将其变换为源二叉树的镜像。数据范围:二叉树的节点数 0≤n≤10000≤n≤1000 , 二叉树每个节点的值 0≤val≤10000≤val≤1000要求: 空间复杂度 O(n)O(n) 。本题也有原地操作,即空间复杂度 O(1)O(1) 的解法,时间复杂度 O(n)O(n)
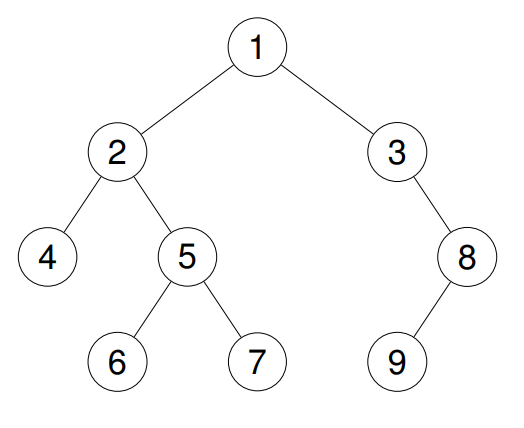
比如:源二叉树

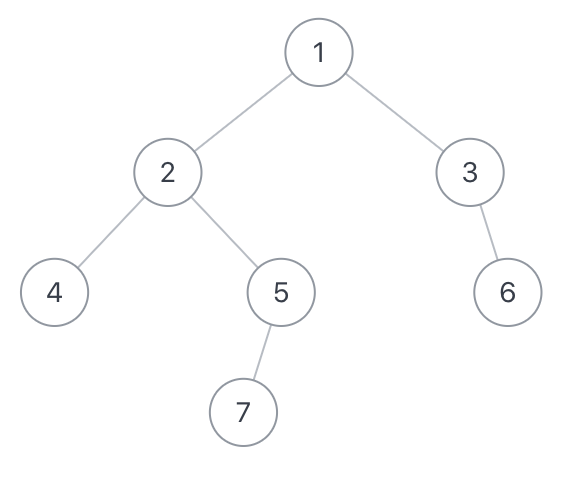
镜像二叉树

思路一 递归
我们镜像二叉树需要交换所有节点的左右孩子,所以我们可以使用递归,将整颗二叉树的镜像问题,分解为镜像所有节点。
public TreeNode Mirror(TreeNode pRoot) {
// 如果节点为空,镜像也为null
if( pRoot == null) return null;
// 使用临时节点变量镜像传过来节点
TreeNode temp = pRoot.left;
pRoot.left = pRoot.right;
pRoot.right = temp;
// 进行递归
Mirrot(pRoot.left);
Mirrot(pRoot.right);
return pRoot;
}思路二 - 栈
二叉树中能够使用递归实现的操作,大多也可以用栈实现。
- step 1:优先检查空树的情况。
- step 2:使用栈辅助遍历二叉树,根节点先进栈。
- step 3:遍历过程中每次弹出栈中一个元素,然后该节点左右节点分别入栈。
- step 4:第三步之后,我们再交换弹出的栈元素的两个子节点的值,因为这两个子节点已经入栈了,入栈之后再交换就不怕后续没有交换。
public TreeNode Mirror (TreeNode pRoot) {
// 判断空节点
if(pRoot == null) return null;
Stack<TreeNode> stack = new Stack<TreeNode>();
// 压入根节点
stack.push(pRoot);
while(!stack.isEmpty()) {
TreeNode node = stack.pop();
//左右节点入栈
if(node.left != null)
stack.push(node.left);
if(node.right != null)
stack.push(node.right);
//交换左右
TreeNode temp = node.left;
node.left = node.right;
node.right = temp;
}
return pRoot;
}JZ78 把二叉树打印成多行
描述
给定一个节点数为 n 二叉树,要求从上到下按层打印二叉树的 val 值,同一层结点从左至右输出,每一层输出一行,将输出的结果存放到一个二维数组中返回。例如:给定的二叉树是{1,2,3,#,#,4,5}

该二叉树多行打印层序遍历的结果是[[1],[2,3],[4,5]]
数据范围:二叉树的节点数 0≤n≤1000,0≤val≤10000要求:空间复杂度 O(n),时间复杂度 O(n)
思路
我们用队列对树进行层次遍历,第一层,根节点先入队,队列中只有一个节点,对应第一层只有一个节点,第一层访问结束后,第一层节点出队,它的子节点刚好都加入了队列,此时队列中的元素个数就是第二层的节点数。因此当我们使用队列对树进行层次遍历时,就可以用数组存储每个节点的值。
import java.util.*;
/*
* public class TreeNode {
* int val = 0;
* TreeNode left = null;
* TreeNode right = null;
* public TreeNode(int val) {
* this.val = val;
* }
* }
*/
public class Solution {
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param pRoot TreeNode类
* @return int整型ArrayList<ArrayList<>>
*/
public ArrayList<ArrayList<Integer>> Print (TreeNode pRoot) {
// write code here
// 定义返回的二维数组res
ArrayList<ArrayList<Integer>> res = new ArrayList<ArrayList<Integer>>();
if(pRoot == null) return res;
// 层次遍历,使用队列,Queue接口
Queue<TreeNode> dq = new LinkedList<TreeNode>();
dq.add(pRoot);
while(!dq.isEmpty()) {
int n = dq.size();
// 临时数组存放每一层的结点值
ArrayList<Integer> temp = new ArrayList<Integer>();
for (int i = 0; i < n; i++) {
temp.add(dq.peek().val);
TreeNode tempNode = dq.poll();
if(tempNode.left != null) dq.add(tempNode.left);
if(tempNode.right != null) dq.add(tempNode.right);
}
res.add(temp);
}
return res;
}
}JZ26 树的子结构
描述
输入两棵二叉树A,B,判断B是不是A的子结构。(我们约定空树不是任意一个树的子结构)假如给定A为{8,8,7,9,2,#,#,#,#,4,7},B为{8,9,2},2个树的结构如下,可以看出B是A的子结构

数据范围:0 <= A的节点个数 <= 100000 <= B的节点个数 <= 10000
思路
层次遍历树的所有节点,然后对每个节点判断该节点是否与root2相同,判断两个节点是否相同采用递归,返回boolean值。注意,这里判断两个节点是否相同并非简单判断root1==rooot2,因为root1可能有多的部分,所以我们使用递归,每个递归节点都判断该节点处的值是否相等,并且增加判断:
当传入双方节点,有一方为空,说明已经递归到了最底层,增加判断:
- 若root1为空,root2不为空,root2肯定不为root1的子树
- 若root1为空,root2为空,该节点父节点处两棵树相同
- 若root1不为空,root2为空,该节点父节点处两棵树相同
import java.util.*;
/**
public class TreeNode {
int val = 0;
TreeNode left = null;
TreeNode right = null;
public TreeNode(int val) {
this.val = val;
}
}
*/
public class Solution {
public boolean HasSubtree(TreeNode root1, TreeNode root2) {
if (root1 == null || root2 == null) return false;
boolean flag = false;
Queue<TreeNode> dq = new LinkedList<TreeNode>();
dq.add(root1);
// 层次遍历访问所有节点
while(!dq.isEmpty()) {
int n = dq.size();
for(int i = 0; i < n; i++){
if(dq.peek().val == root2.val) {
flag = sameTree(dq.peek(), root2, true);
if(flag) return flag;
}
TreeNode temp = dq.poll();
if(temp.left != null) dq.add(temp.left);
if(temp.right != null) dq.add(temp.right);
}
}
return flag;
}
public boolean sameTree(TreeNode root1, TreeNode root2, boolean flag) {
// 整个递归过程中,一旦flag为false,说明root2不是root1的子结构
if(!flag) return false;
// 当传入双方节点,有一方为空,说明已经递归到了最底层,增加判断:
// 1.若root1为空,root2不为空,root2肯定不为root1的子树
// 2.若root1为空,root2为空,该节点父节点处两棵树相同
// 3.若root1不为空,root2为空,该节点父节点处两棵树相同
if(root1 == null || root2 == null) {
if(root2 == null && root1 != null) return true;
if(root1 == null && root2 != null) return false;
if(root1 == null && root2 == null) return true;
}
flag = sameTree(root1.left, root2.left, flag);
flag = sameTree(root1.right, root2.right, flag);
// 每个递归节点都判断该节点处的值是否相等
if(flag) {
if(root2 == null || root1.val == root2.val) return true;
if(root2 != null && root1.val == root2.val) return true;
if(root2 != null && root1.val != root2.val) return false;
}
return flag;
}
}JZ86 在二叉树中找到两个节点的最近公共祖先
描述
给定一棵二叉树(保证非空)以及这棵树上的两个节点对应的val值 o1 和 o2,请找到 o1 和 o2 的最近公共祖先节点。
注:本题保证二叉树中每个节点的val值均不相同。

所以节点值为5和节点值为1的节点的最近公共祖先节点的节点值为3,所以对应的输出为3。节点本身可以视为自己的祖先
思路一 非递归
从根节点到目标节点1会有一个路径,我们将该路径上的祖先节点保存下来,然后从根节点到目标节点2也会又一个路径,我们也将路径上的祖先节点保存下来,然后比较两个路径中第一个相同的节点,就得到了最近的公共祖先节点。
寻找路径,可以通过遍历二叉树,选择层次遍历,因为层次遍历可以不用遍历完树的所有节点。例如目标节点是0和8,只需要遍历树的三层,如果采用深度优先搜索dfs,则需要将根节点的左子树全部遍历完,再遍历根节点右子树,才能找到0和8。
代码实现:
使用HashMap存储节点值和节点的祖先节点,节点值作为key,祖先节点的值作为value,然后使用Set结构存储o1到根节点的路径,再判断o2是否在该路径上,不在就判断o2的父亲节点是否在,直到根节点。
详细思路都在注释上
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param root TreeNode类
* @param o1 int整型
* @param o2 int整型
* @return int整型
*/
public int lowestCommonAncestor (TreeNode root, int o1, int o2) {
// write code here
Map<Integer, Integer> parent = new HashMap<>();
// 根节点没有祖先节点,给一个默认值
parent.put(root.val, -1);
// 通过层次遍历,遍历所有节点,直到遇到目标节点o1和o2
Queue<TreeNode> dq = new LinkedList<>();
dq.add(root);
// parent中包含了o1和o2就说明目标节点都遇到了
while(!parent.containsKey(o1) || !parent.containsKey(o2)) {
TreeNode temp = dq.poll();
if(temp.left != null) {
// 该节点左子树不为空,记录左子树节点的祖先节点,并将该节点入队
parent.put(temp.left.val, temp.val);
dq.add(temp.left);
}
if(temp.right != null) {
parent.put(temp.right.val, temp.val);
dq.add(temp.right);
}
}
// 目标节点都已经保存在Map parent中,接下来寻找两个目标节点到根节点的路径,路径第一个重合的值,就是最近公共祖先,根节点肯定是两个节点路径上值相同的。
// 这里要注意的是节点本身也可以视为自己的祖先
Set<Integer> ancestors = new HashSet<>();
// 记录了o1和他的祖先节点,直到根节点
while(parent.containsKey(o1)) {
ancestors.add(o1);
o1 = parent.get(o1); // o1本身变成了祖先节点的值
}
// 查看o1到根节点的路径上,是否包含o2,不包含就查看o2的父节点
while(!ancestors.contains(o2)) {
o2 = parent.get(o2);
}
return o2;
}思路二 递归
有这么几种情况:
- 如果o1或o2与root匹配,说明最近公共祖先就是root
- 如果都不匹配,就递归左右子树
- 如果有一个目标节点出现在左子树,另一个出现在右子树,则root就是最近公共祖先
- 如果两个节点都出现在左子树,则说明最近公共祖先在左子树,否则在右子树
- 继续递归,直到遇到1或3的情况
public int lowestCommonAncestor (TreeNode root, int o1, int o2) {
// write code here
if(root == null) return -1;
// 该节点是目标节点中的某一个
if(root.val == o1 || root.val == o2) return root.val;
int left = lowestCommonAncestor(root.left, o1, o2);
int right = lowestCommonAncestor(root.right, o1, o2);
// 左子树没找到,则在右子树中
if(left == -1) {
return right;
}
// 右子树没找到,则在左子树中
if(right == -1) {
return left;
}
// 否则是当前节点
return root.val;
}
JZ84 二叉树中和为某一值的路径(三)
描述
给定一个二叉树root和一个整数值 sum ,求该树有多少路径的的节点值之和等于 sum 。
- 该题路径定义不需要从根节点开始,也不需要在叶子节点结束,但是一定是从父亲节点往下到孩子节点
- 总节点数目为n
- 保证最后返回的路径个数在整形范围内
假如二叉树root为{1,2,3,4,5,4,3,#,#,-1},sum=6,那么总共如下所示,有3条路径符合要求

思路 二叉树递归
我们需要找到树中路径和为指定值的路径,首先我们需要确定路径的起点,这可能是树中的任意节点,所以我们需要遍历这棵树,来确定路径的起点,这里采用(根左右)前序遍历,这样就不会回溯。
//以其子结点为新根
FindPath(root.left, sum);
FindPath(root.right, sum);
通过前序遍历树中的每个节点,将每个节点看作一棵新的子树,然后以子树根节点为起点,对每个子树还要采用一次遍历,判断有没有路径和是否与指定sum相等。
可以通过每递归一个子节点,就减去该节点的val,直到递归到某个节点的val等于sum,就找到了一个路径。这里值得注意的是,即使找到了一个路径,还需要继续遍历到叶子结点,因为值存在负值,所以路径会存在子集关系。
//进入子节点继续找
dfs(root.left, sum - root.val);
dfs(root.right, sum - root.val);
//符合目标值
if(sum == root.val)
res++;
- 每次将原树中遇到的节点作为子树的根节点送入dfs函数中查找有无路径,如果该节点为空则返回。
- 然后递归遍历这棵树每个节点,每个节点都需要这样操作
- 在dfs函数中,也是往下递归,遇到一个节点就将sum减去节点值再往下
- 剩余的sum等于当前节点值则找到一种情况。
代码实现:
public class Solution {
// 使用res记录多少条路径的节点值和等于sum
private int res = 0;
public int FindPath (TreeNode root, int sum) {
// write code here
// 通过先序遍历,遍历所有节点,对每个节点也使用先序遍历都向下计算路径和,直到叶子结点,因为负值也需要被考虑
if(root == null) return res;
dfs(root, sum);
// 递归原树的每一个节点,每个节点都对应一棵子树
if(root.left != null) res = FindPath(root.left, sum);
if(root.right != null) res = FindPath(root.right, sum);
return res;
}
// 递归每棵子树,找路径
public void dfs(TreeNode root, int sum) {
if(root == null) return;
if(root.val == sum) {
res++;
// return; // 即使找到了一个路径,也需要继续执行递归,因为存在负值,路径会存在子集关系
}
if(root.left != null) dfs(root.left, sum - root.val);
if(root.right != null) dfs(root.right, sum - root.val);
}