剑指offer-链表
JZ24 反转链表
描述
给定一个单链表的头结点pHead(该头节点是有值的,比如在下图,它的val是1),长度为n,反转该链表后,返回新链表的表头。数据范围: 0≤n≤10000≤n≤1000要求:空间复杂度 O(1)O(1) ,时间复杂度 O(n)O(n) 。如当输入链表{1,2,3}时,经反转后,原链表变为{3,2,1},所以对应的输出为{3,2,1}。以上转换过程如下图所示:

思路一 — 头插法
没有头结点的头插法
public class ReverseList {
public static void main(String[] args) {
ListNode head = new ListNode(1);
head.next = new ListNode(2);
head.next.next = new ListNode(3);
ListNode reverseLink = Reverse(head);
System.out.println(reverseLink.val);
}
public static ListNode Reverse(ListNode head) {
// write code here
ListNode tail, temp;
if (head == null) {
tail = head;
} else {
tail = new ListNode(head.val);
while (head.next != null) {
head = head.next;
// 头插创建新链表
temp = new ListNode(head.val);
temp.next = tail;
tail = temp;
}
}
return tail;
}
}
class ListNode {
int val;
ListNode next = null;
public ListNode(int val) {
this.val = val;
}
}思路二 — 栈
先将链表所有元素放入栈中,然后出栈
public ListNode ReverseList (ListNode head) {
// write code here
Stack<Integer> stack = new Stack<>();
// 进栈
while(head != null) {
stack.push(head.val);
head = head.next;
}
if(stack.isEmpty()) return head;
// 出栈,并将值赋给新链表
ListNode temp = new ListNode(stack.pop());
ListNode tail = temp;
while (!stack.isEmpty()) {
ListNode tempNode = new ListNode(stack.pop());
temp.next = tempNode;
temp = temp.next;
}
return tail;
}思路三 — 迭代
将链表反转,就是将每个表元的指针从向后变成向前,那我们可以遍历原始链表,将遇到的节点一一指针逆向即可。指针怎么逆向?不过就是断掉当前节点向后的指针,改为向前罢了。
具体做法:
- step 1:优先处理空链表,空链表不需要反转。
- step 2:我们可以设置两个指针,一个当前节点的指针,一个上一个节点的指针(初始为空)。
- step 3:遍历整个链表,每到一个节点,断开当前节点与后面节点的指针,并用临时变量记录后一个节点,然后当前节点指向上一个节点,即可以将指针逆向。
- step 4:再轮换当前指针与上一个指针,让它们进入下一个节点及下一个节点的前序节点。
public ListNode ReverseList (ListNode head) {
// write code here
if(head == null) return head;
ListNode pre = null;
ListNode cur = head;
while (cur != null) {
ListNode temp = cur.next;
cur.next = pre;
pre = cur;
cur = temp;
}
return pre;
}JZ25 合并两个排序的链表
描述
输入两个递增的链表,单个链表的长度为n,合并这两个链表并使新链表中的节点仍然是递增排序的。
数据范围: 0≤n≤10000≤n≤1000,−1000≤节点值≤1000−1000≤节点值≤1000
要求:空间复杂度 O(1)O(1),时间复杂度 O(n)O(n)
如输入{1,3,5},{2,4,6}时,合并后的链表为{1,2,3,4,5,6},所以对应的输出为{1,2,3,4,5,6},转换过程如下图所示:

思路一
将一个链表节点按照顺序插入另一个链表,使用这个方法的难点是确定第二个链表插入第一个链表的合适位置
public ListNode Merge (ListNode pHead1, ListNode pHead2) {
// write code here
// 如果存在空链表
if(pHead2 == null) return pHead1;
if(pHead1 == null) return pHead2;
// 利用pHead指向pHead1,方便对pHead1进行操作
ListNode pHead = pHead1;
ListNode temp = null;
// 将pHead2链表节点按正确顺序插入到pHead1链表
// 指针在pHead1进行循环查找pHead2第一个结点应该插入到pHead1的合适位置
while(pHead1.next != null && pHead2 != null) {
// pHead2第一个结点可能比pHead1指针指向的元素大(插入后面),也有可能小(插入前面)
if(pHead1.val <= pHead2.val && pHead1.next.val >= pHead2.val) { // 插入后面
temp = pHead1.next;
ListNode newNode = new ListNode(pHead2.val);
pHead1.next = newNode;
newNode.next = temp;
pHead2 = pHead2.next;
} else if(pHead1.val > pHead2.val) { // pHead2的第一个结点比pHead1指针指向的元素小,插入前面
ListNode newNode1 = new ListNode(pHead2.val);
newNode1.next = pHead1;
pHead1 = newNode1;
pHead2 = pHead2.next;
pHead = pHead1;
}
pHead1 = pHead1.next;
}
// 上面的循环还未讨论pHead1最后一个结点和pHead2之间的关系
while(pHead1 != null && pHead2 != null) {
if(pHead1.val <= pHead2.val) {
pHead1.next = pHead2;
pHead2 = null;
} else if(pHead1.val > pHead2.val) { // pHead2的第一个结点比pHead1指针指向的元素小,插入前面
temp = pHead1;
pHead1.val = pHead2.val;
pHead1.next = temp;
pHead2 = pHead2.next;
}
pHead1 = pHead1.next;
}
// 如果指针循环到pHead1末尾,然后pHead2还有元素没有插入,说明pHead2剩下的元素都比pHead1大,拼接到尾端即可
return pHead;
}思路二 — 双指针迭代
这道题既然两个链表已经是排好序的,都是从小到大的顺序,那我们要将其组合,可以使用归并排序的思想:每次比较两个头部,从中取出最小的元素,然后依次往后。这样两个链表依次往后,我们肯定需要两个指针同方向访问才能实现。
public ListNode Merge (ListNode pHead1, ListNode pHead2) {
// write code here
// 如果有一个链表为null,那么返回另一个链表即可,即使另一个链表也为null
if(pHead1 == null) return pHead2;
if(pHead2 == null) return pHead1;
// 分别使用指针指向两个链表,然后比较两个指针指向值的大小,将小的拼接到新链表中,并将小指针后移
// 创建带头节点的新链表,用以返回
ListNode head = new ListNode(0);
ListNode cur = head;
while(pHead1 != null && pHead2 != null) {
if(pHead1.val <= pHead2.val) {
cur.next = pHead1;
pHead1 = pHead1.next;
} else {
cur.next = pHead2;
pHead2 = pHead2.next;
}
cur = cur.next;
}
if(pHead1 != null) cur.next = pHead1;
if(pHead2 != null) cur.next = pHead2;
// 返回头节点以后的链表
return head.next;
}JZ52两个链表的第一个公共结点
描述
输入两个无环的单向链表,找出它们的第一个公共结点,如果没有公共节点则返回空。(注意因为传入数据是链表,所以错误测试数据的提示是用其他方式显示的,保证传入数据是正确的)数据范围: n≤1000n≤1000
要求:空间复杂度 O(1),时间复杂度 O(n)
例如,输入{1,2,3},{4,5},{6,7}时,两个无环的单向链表的结构如下图所示:

可以看到它们的第一个公共结点的结点值为6,所以返回结点值为6的结点。
思路一 — 暴力循环两个链表
使用一个临时指针temp遍历某一个链表,然后temp每指向一个链表结点,另一个链表会遍历一遍,看是否有能够与temp结点相等的结点,如果有说明这就是公共结点,没有则返回null,时间复杂度是O(n*n)
public ListNode FindFirstCommonNode(ListNode pHead1, ListNode pHead2) {
// 暴力循环两个链表
while (pHead1 != null) {
ListNode temp = pHead2;
while(temp != null) {
if(pHead1 == temp) {
return pHead1;
}
temp = temp.next;
}
pHead1 = pHead1.next;
}
return null;
}思路二 — 双指针

如果A和B链表长度相等,问题就十分简单,可以使用双指针。
- 初始化:指针ta指向链表A头结点,指针tb指向链表B头结点
- 如果ta == tb, 说明找到了第一个公共的头结点,直接返回即可。
- 否则,ta != tb,则++ta,++tb
假设链表A长度为a, 链表B的长度为b,此时a != b, 但是,a+b == b+a因此,可以让a+b作为链表A的新长度,b+a作为链表B的新长度。
对于某个指针p1来说,其实就是让它跑了连接好的的链表,长度就变成一样了。如果有公共结点,那么指针一起走到末尾的部分,也就一定会重叠。

分析下两个指针的路径:
ta: 1-2-4-5-(此时遇到null)-(-2)-(-1)-0-4-5-null
tb: (-2)-(-1)-0-4-5-null(此时遇到null)-1-2-4-5-null
因此,两个指针所要遍历的链表就长度一样了!如果两个链表存在公共结点,那么p1就是该结点,如果不存在那么p1将会是null。
public ListNode FindFirstCommonNode(ListNode pHead1, ListNode pHead2) {
// 双指针
if (pHead1 == null || pHead2 == null) return null;
ListNode temp1 = pHead1;
ListNode temp2 = pHead2;
while(temp1 != temp2) {
temp1 = temp1.next;
temp2 = temp2.next;
if(temp1 != temp2) {
if(temp1 == null) temp1 = pHead2;
if(temp2 == null) temp2 = pHead1;
}
}
return temp1;
}JZ23 链表中环的入口结点
描述
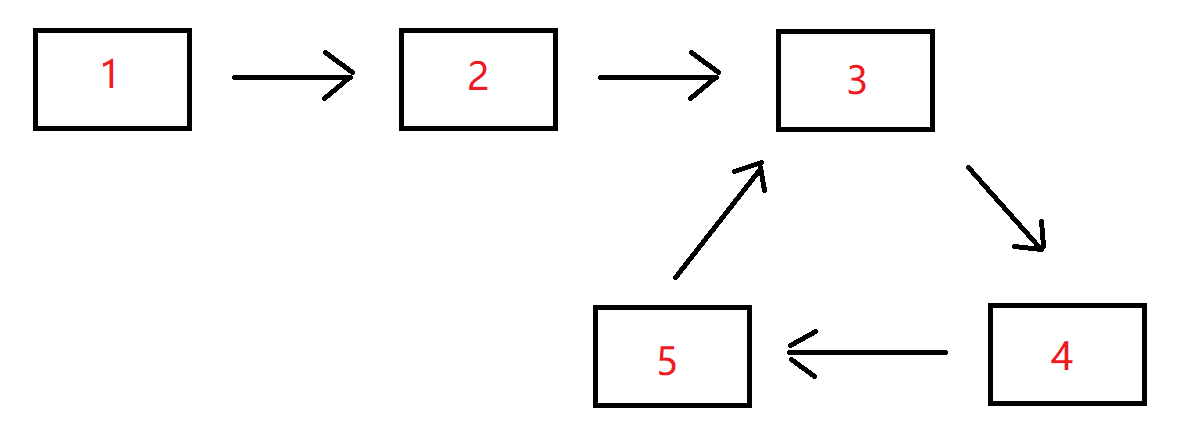
给一个长度为n链表,若其中包含环,请找出该链表的环的入口结点,否则,返回null。数据范围: n≤10000n≤10000,1<=结点值<=100001<=结点值<=10000要求:空间复杂度 O(1),时间复杂度 O(n)例如,输入{1,2},{3,4,5}时,对应的环形链表如下图所示:

可以看到环的入口结点的结点值为3,所以返回结点值为3的结点。
思路

note: 这里的结点P也就是node 2
import java.util.*;
/*
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}
*/
public class Solution {
public ListNode EntryNodeOfLoop(ListNode pHead) {
if (pHead == null) return pHead;
ListNode fast = pHead;
ListNode slow = pHead;
slow = isExistNodeOfLoop(fast, slow);
if(slow == null) return null;
// fast = pHead;
while(slow != fast) {
slow = slow.next;
fast = fast.next;
}
return fast;
}
ListNode isExistNodeOfLoop(ListNode fast, ListNode slow) {
while (fast != null && fast.next != null) {
fast = fast.next.next;
slow = slow.next;
if (slow == fast) {
// 存在环
return slow;
}
}
return null;
}
}